
Sử dụng proxy 4G cho Web Crawling
Nếu không có proxy, việc thu thập dữ liệu sẽ bị hạn chế và không thể hoàn thành khối lượng lớn công việc.
Web Crawling để làm gì?
Web Crawling là gì?
Web Crawling (thu thập dữ liệu web) là quá trình sử dụng bot hoặc chương trình tự động để truy cập và lấy thông tin từ các trang web một cách có hệ thống. Các bot này được gọi là web crawlers hoặc spiders (nhện web), chúng duyệt qua các liên kết, thu thập dữ liệu và lưu trữ để sử dụng sau này.
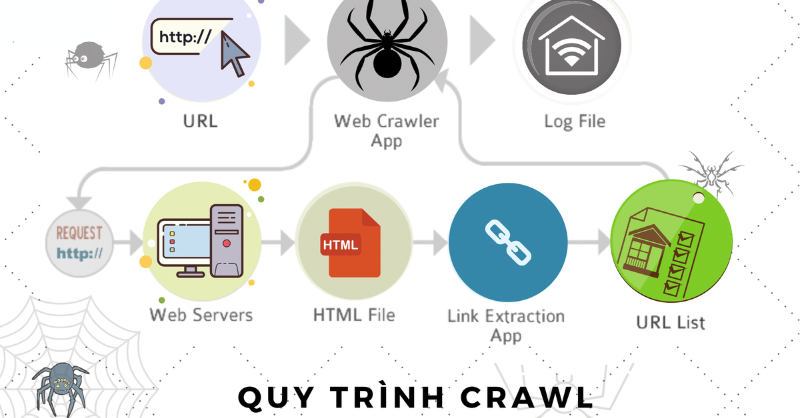
Web Crawler hoạt động như thế nào?
1️⃣ Bắt đầu từ một URL gốc (seed URL)
2️⃣ Tải nội dung trang web (HTML, hình ảnh, dữ liệu)
3️⃣ Tìm và theo dõi các liên kết trên trang để mở rộng phạm vi thu thập
4️⃣ Lưu trữ dữ liệu trong cơ sở dữ liệu hoặc file để phân tích sau này
Web Crawling được sử dụng để làm gì?
- SEO & Phân tích website (Googlebot thu thập trang để lập chỉ mục)
- So sánh giá sản phẩm (eCommerce tracking, tìm giá tốt nhất)
- Theo dõi tin tức & nghiên cứu thị trường
- Thu thập dữ liệu AI & Machine Learning
- Phân tích mạng xã hội & xu hướng
Tuy nhiên, nhiều trang web có cơ chế bảo vệ chống web crawling như CAPTCHA, chặn IP, robots.txt, vì vậy cần sử dụng proxy 4G hoặc IP xoay để tránh bị phát hiện khi crawling dữ liệu quy mô lớn.
Tại sao cần sử dụng proxy 4G cho web crawling
Một trong những thách thức lớn nhất khi thu thập dữ liệu từ web là việc bị trang web chặn do gửi quá nhiều yêu cầu từ cùng một địa chỉ IP. Nếu không có proxy, việc thu thập dữ liệu sẽ bị hạn chế và không thể hoàn thành khối lượng lớn công việc. Proxy 4G giúp giải quyết vấn đề này bằng cách sử dụng địa chỉ IP từ các nhà mạng di động như Viettel, Mobifone, Vinaphone, khiến việc crawling trở nên tự nhiên hơn.
Không giống như proxy datacenter thường bị phát hiện dễ dàng, proxy 4G có tính năng xoay IP tự động theo thời gian hoặc theo yêu cầu. Điều này giúp giảm nguy cơ bị chặn, đảm bảo quá trình thu thập dữ liệu diễn ra liên tục.
Ngoài ra, việc sử dụng proxy 4G giúp tăng tính bảo mật và ẩn danh cho các hoạt động crawling, tránh bị theo dõi và giới hạn bởi các nền tảng trực tuyến.

Lợi ích của proxy 4G khi thực hiện web crawling
Proxy 4G mang lại nhiều lợi ích đáng kể khi thực hiện web crawling, giúp tối ưu hiệu suất và giảm thiểu các vấn đề có thể gặp phải.
💡 Đầu tiên, proxy 4G có khả năng thay đổi IP liên tục một cách tự nhiên nhờ vào hệ thống mạng di động. Điều này giúp các yêu cầu gửi đi không bị đánh dấu là spam, giảm thiểu nguy cơ bị chặn.
💡 Một lợi ích khác là tốc độ và độ tin cậy cao. Proxy 4G cung cấp IP từ các nhà mạng uy tín, đảm bảo kết nối ổn định và nhanh chóng. Khi sử dụng proxy datacenter, nhiều trang web có thể nhận diện và từ chối kết nối, nhưng với proxy 4G, hệ thống bảo mật của các trang web sẽ khó phát hiện hơn do IP trông giống như một người dùng thực.
💡 Việc sử dụng proxy 4G còn giúp tối ưu chi phí. Mặc dù giá thành của proxy 4G có thể cao hơn so với proxy thông thường, nhưng hiệu quả mà nó mang lại sẽ giúp tiết kiệm nhiều thời gian và công sức khi thực hiện web crawling. Thay vì phải đầu tư vào nhiều địa chỉ IP riêng lẻ, proxy 4G cho phép sử dụng luân phiên, giúp tối ưu tài nguyên và tránh bị giới hạn bởi các nền tảng.

Cách thiết lập proxy 4G để crawling hiệu quả
Để sử dụng proxy 4G cho web crawling, trước tiên cần chọn nhà cung cấp proxy uy tín. Một số nhà cung cấp proxy 4G tại Việt Nam như mProxy.vn, ProxyViet, hoặc Proxy 4G Việt Nam cung cấp các giải pháp proxy ổn định, đảm bảo tốc độ cao và IP xoay liên tục.

Sau khi có proxy 4G, bước tiếp theo là tích hợp vào trình crawler. Hầu hết các công cụ crawling như Scrapy, Selenium, Puppeteer đều hỗ trợ sử dụng proxy. Trong Python, có thể sử dụng thư viện requests hoặc BeautifulSoup kết hợp với proxy để thực hiện crawling mà không bị chặn.
Khi sử dụng proxy 4G, cần theo dõi và thay đổi IP định kỳ để tránh bị phát hiện. Một số nhà cung cấp proxy có API để thay đổi IP theo yêu cầu, giúp quá trình crawling diễn ra thuận lợi hơn.
Những lưu ý quan trọng khi sử dụng proxy 4G để crawling
Mặc dù proxy 4G mang lại nhiều lợi ích, nhưng cũng cần lưu ý một số điểm để tránh gặp rủi ro khi thực hiện crawling. Trước tiên, cần đảm bảo rằng proxy 4G được sử dụng từ nguồn uy tín, tránh các proxy kém chất lượng có thể bị đánh dấu hoặc sử dụng chung với nhiều người khác.
Thứ hai, không nên gửi quá nhiều yêu cầu trong một khoảng thời gian ngắn. Dù sử dụng proxy 4G, nếu tần suất gửi request quá cao, trang web vẫn có thể phát hiện và áp dụng các biện pháp bảo vệ như yêu cầu xác thực CAPTCHA hoặc chặn IP. Do đó, cần thiết lập tần suất hợp lý, mô phỏng hành vi người dùng thực để tránh bị phát hiện.

Ngoài ra, nếu crawling các trang web có chính sách bảo vệ dữ liệu nghiêm ngặt, cần kiểm tra điều khoản sử dụng để đảm bảo rằng việc thu thập dữ liệu không vi phạm quy định. Một số trang web có thể có API chính thức để truy xuất dữ liệu, đây cũng là một lựa chọn thay thế để thu thập thông tin hợp pháp mà không cần sử dụng crawling.
Proxy 4G là một công cụ mạnh mẽ giúp tối ưu quá trình web crawling, giảm nguy cơ bị chặn và tăng hiệu suất thu thập dữ liệu. Nhờ vào tính năng xoay IP tự động, độ tin cậy cao và khả năng ẩn danh tốt, proxy 4G là giải pháp lý tưởng cho các dự án crawling quy mô lớn. Tuy nhiên, để đạt được hiệu quả tối đa, cần lựa chọn nhà cung cấp proxy uy tín, điều chỉnh tần suất crawling hợp lý và tuân thủ các quy định về quyền riêng tư của trang web.