
Sử dụng Web Crawling hay Web Scraping để thu thập dữ liệu an toàn với proxy 4G
Cả Web Crawling và Web Scraping đều là công cụ mạnh mẽ giúp thu thập dữ liệu từ Internet.

Trong thời đại số hóa, dữ liệu là tài sản quý giá. Hai phương pháp phổ biến để thu thập dữ liệu từ web là Web Crawling và Web Scraping. Mặc dù có nhiều điểm tương đồng, nhưng chúng phục vụ các mục đích khác nhau và có ưu, nhược điểm riêng. Hãy cùng khám phá sự khác biệt giữa hai phương pháp này.
Web Crawling là gì?
Định nghĩa
Web Crawling (thu thập dữ liệu web) là quá trình tự động duyệt và lập chỉ mục các trang web bằng cách theo dõi các liên kết từ trang này sang trang khác. Các công cụ thực hiện quá trình này được gọi là web crawlers hoặc bots.
Ứng dụng
- Công cụ tìm kiếm (Google, Bing, Yahoo): Thu thập dữ liệu để lập chỉ mục và xếp hạng trang web.
- Phân tích trang web: Kiểm tra cấu trúc và hiệu suất trang.
- Giám sát thay đổi nội dung: Theo dõi cập nhật trên các website quan trọng.
Ưu điểm
✅ Tự động hóa quá trình thu thập dữ liệu trên quy mô lớn.
✅ Hữu ích trong việc lập chỉ mục và tổ chức dữ liệu web.
✅ Dễ dàng phát hiện nội dung mới hoặc được cập nhật.
Nhược điểm
❌ Cần tài nguyên lớn để thu thập và xử lý dữ liệu.
❌ Có thể bị chặn bởi các trang web nếu không tuân thủ robots.txt.
❌ Không trích xuất dữ liệu cụ thể mà chỉ lập chỉ mục nội dung.
Web Scraping là gì?
Định nghĩa
Web Scraping (trích xuất dữ liệu web) là quá trình thu thập dữ liệu cụ thể từ một trang web. Nó không chỉ duyệt qua các trang mà còn trích xuất các phần thông tin cụ thể như giá sản phẩm, bài viết, danh sách khách hàng, v.v.
Ứng dụng
- Thu thập giá sản phẩm từ các trang thương mại điện tử (Amazon, Shopee, Lazada).
- Theo dõi tin tức hoặc bài viết từ các trang báo mạng.
- Tạo cơ sở dữ liệu khách hàng từ các trang doanh nghiệp.
Ưu điểm
✅ Trích xuất dữ liệu có mục tiêu, tiết kiệm thời gian.
✅ Có thể xử lý nhiều định dạng dữ liệu như văn bản, hình ảnh, bảng số liệu.
✅ Hỗ trợ nhiều ngôn ngữ lập trình như Python (BeautifulSoup, Scrapy), JavaScript (Puppeteer, Selenium).
Nhược điểm
❌ Một số trang web có chính sách bảo vệ dữ liệu, khiến scraping trở nên khó khăn.
❌ Cần viết mã tùy chỉnh cho từng trang web khác nhau.
❌ Có thể bị chặn IP hoặc yêu cầu xác thực nếu thực hiện quá nhiều yêu cầu trong thời gian ngắn.

Sự khác biệt giữa Web Crawling và Web Scraping
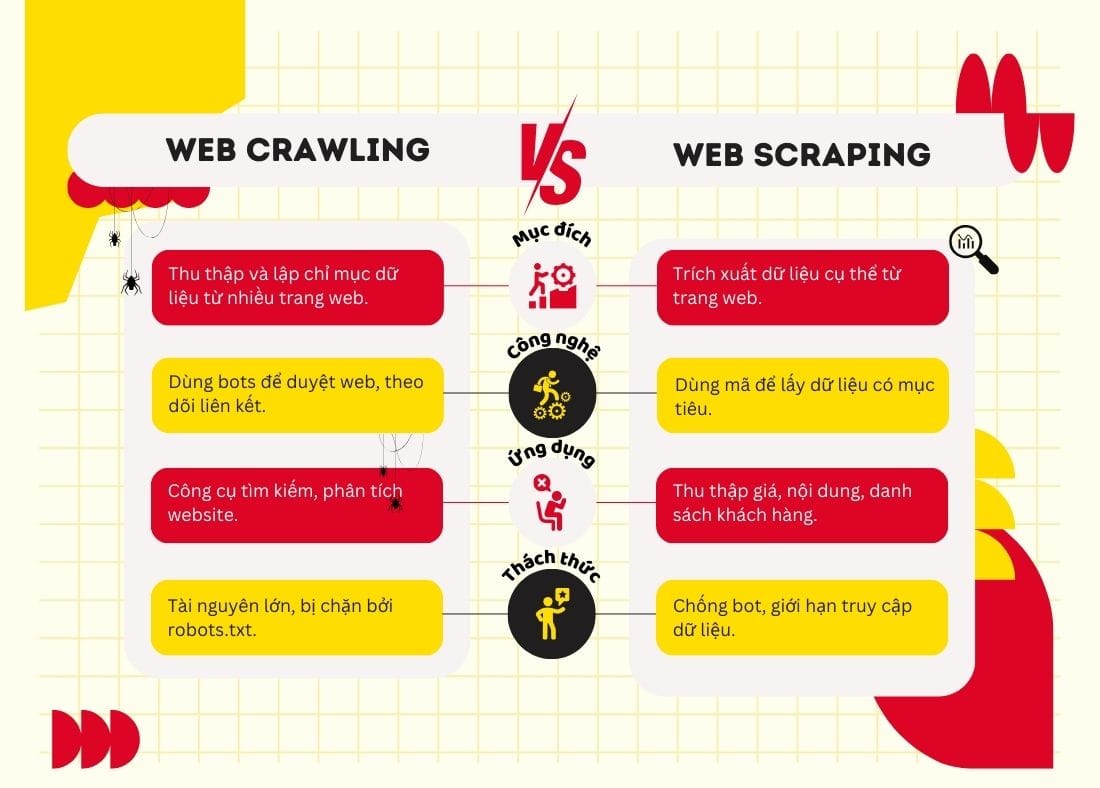
Proxy 4G có tác động gì đến Web Crawling và Web Scraping?
Lợi ích của Proxy 4G
- Giảm nguy cơ bị chặn IP: Các trang web thường giới hạn số lượng yêu cầu từ một địa chỉ IP. Proxy 4G giúp thay đổi IP thường xuyên, giảm khả năng bị phát hiện.
- Tăng tính ẩn danh: Các địa chỉ IP 4G thuộc nhà mạng di động, khó bị phân biệt với người dùng thực.
- Tốc độ và tính ổn định cao: Proxy 4G thường có tốc độ ổn định và ít bị giới hạn so với proxy thông thường.
Nhược điểm của Proxy 4G
- Chi phí cao hơn: So với proxy thông thường (data center proxy), proxy 4G có giá cao hơn do sử dụng hạ tầng di động.
- IP động liên tục: Việc xoay IP có thể gây gián đoạn nếu yêu cầu truy vấn cần duy trì địa chỉ IP cố định trong một khoảng thời gian dài.
Khi nào nên sử dụng Proxy 4G?
- Khi thực hiện Web Scraping trên các trang web có bảo vệ mạnh, dễ chặn bot.
- Khi cần ẩn danh tốt hơn so với proxy trung tâm dữ liệu.
- Khi muốn mô phỏng hành vi người dùng thực tế để tránh bị phát hiện.

Lựa chọn nào phù hợp? Web Crawling hay Web Scraping?
- Nếu bạn cần lập chỉ mục nội dung trên nhiều trang web, Web Crawling là lựa chọn phù hợp.
- Nếu bạn muốn thu thập thông tin cụ thể từ một số trang web nhất định, Web Scraping là phương pháp hiệu quả hơn.
- Nếu bạn gặp các giới hạn IP hoặc CAPTCHA, sử dụng proxy 4G có thể giúp cải thiện khả năng truy cập.
- Để tránh vi phạm chính sách trang web, hãy kiểm tra robots.txt và sử dụng proxy hoặc API chính thức.
Cả Web Crawling và Web Scraping đều là công cụ mạnh mẽ giúp thu thập dữ liệu từ Internet. Việc lựa chọn phương pháp nào phụ thuộc vào mục đích của bạn: Crawling để lập chỉ mục dữ liệu, Scraping để trích xuất thông tin cụ thể.
Khi thực hiện trên các trang web có bảo vệ mạnh, proxy 4G có thể giúp vượt qua giới hạn và tăng tính ẩn danh, nhưng cũng đi kèm với chi phí cao hơn. Hãy lựa chọn giải pháp phù hợp để đảm bảo tính hợp pháp và hiệu quả!